
Содержание

Для этого нужно вычислить вероятность получить датапоинтов в предположении постоянных, но пока неизвестных параметров. Благодаря независимости измерений, мы получим произведение вероятностей реализации каждого измерения. Если мыслить полученную величину как функцию параметров (функция правдоподобия) и найти её максимум, мы получим оценку параметров. Зачастую вместо функции правдоподобия используют ее логарифм — дифференцировать его проще, а результат — тот же. Цель регрессии — найти коэффициенты этой линейной комбинации, и тем самым определить регрессионную функцию (которую также называют моделью). Отмечу, что линейную регрессию называют линейной именно из-за линейной комбинации базисных функций — это не связано с самыми базисными функциями (они могут быть линейными или нет).
— -мерное линейное подпространство (мы считаем фичи линейно независимыми), линейная регрессия это оболочка вектор-столбцов . Итак, если принадлежит , то мы можем найти решение, если нет — будем искать, так сказать, лучшее из нерешений. — вариация остатков, то есть вариация отклонений от регрессионной модели — от нужно отнять предсказание модели и найти вариацию. Точки генерируются случайно по распределению Гаусса с заданным средним и вариациями. Там научат не только основам матанализа, но и непосредственной разработке программного обеспечения с нуля.
Это легко представить для модели с одним признаком, так как уравнение линейной модели совпадает с уравнением прямой, которое мы изучали в средней школе. Для большего числа признаков применима та же механика, однако ее не так легко визуализировать. Представьте, что у нас есть линейная модель только с одной характеристикой , чтобы было легче построить график. На следующем рисунке синие точки представляют наши экземпляры данных, для которых у нас есть значение цели (например, цена дома) и значение одной характеристики (например, квадратных метров дома). Зависимой переменной Y при некоторых заданных значениях независимых переменных (регрессоров). Эмпирическая линейная регрессионная функция определяет регрессионную гиперплоскость в линейном k-мерном пространстве.
Как видно из иллюстрации, расстояние от точки до прямой можно понимать по-разному, например геометрически — это длина перпендикуляра. Однако в контексте нашей задачи нам нужно функциональное расстояние, а не геометрическое. Нас интересует разница между экспериментальным значением и предсказанием модели для каждого поэтому измерять нужно вдоль оси . Цель этой статьи — рассказать о линейной регрессии, а именно собрать и показать формулировки и интерпретации задачи регрессии с точки зрения математического анализа, статистики, линейной алгебры и теории вероятностей. Хотя в учебниках эта тема изложена строго и исчерпывающе, ещё одна научно-популярная статья не помешает.
Проще говоря, линейная регрессия – это статистический тест, применяемый к набору данных для определения и количественной оценки взаимосвязи между рассматриваемыми переменными. Он прост в использовании и до сих пор считается одним из самых мощных алгоритмов. Ко всей этой затее с трансформированием есть более практичный подход. Такая компьютерная процедура называется локальным сглаживаем. Доходы для 18-летних или 70-летних не будут иметь ничего общего с доходом 35-летних, и поэтому получат нулевой вес при взвешивании. Более разумно использовать компьютер для нахождения этой локальной информации, чем пускаться в охоту за формой (математической функцией), которая по счастливой случайности будет иметь изгибы в нужных местах.
Обработчик позволяет построить модель продаж, где в качестве входной переменной будет использоваться цена, а в качестве выходной – объем продаж. После этапа обучения модель готова для использования – в полученную функцию (модель) нужно подставить интересующий набор x-ов и вычислить её значение, которое и будет являться прогнозом. Мы устанавливаем параметры модели (Θi) на определенное значение (обычно случайное) и вычисляем эту ошибку для всех обучающих данных. MAE – стандартная ошибка аппроксимации (насколько в среднем фактическое значение Y отклоняется от расчетного) в % выражении. Интервалы предсказания для средних значений – сохраняется верхняя и нижняя граница, в которых может оказаться среднее значение Y (для совокупности подобных объектов) с указанной вероятностью.
Ранее мы пришли к функции потерь из соображений удобства, но к ней же можно прийти с помощью теории вероятностей и метода максимального правдоподобия (ММП). Предположим, у нас есть независимых одинаково распределенных случайных величин (в нашем случае — результатов измерений). Мы знаем вид функции распределения (напр. нормальное распределение), но хотим определить параметры, которые в нее входят (например и ).
Средняя абсолютная ошибка (MAE)
Поля этой статьи слишком узки, чтобы касаться этой темы, за подробностями советую обратиться к курсу лекций К.В.Воронцова. Где — размер выборки, — количество независимых переменных. Следя за , мы можем вовремя остановиться и перестать добавлять дополнительные степени свободы. — вариация регрессии, то есть вариация предсказаний регрессионной модели в точках (обратите внимание, что среднее предсказаний модели совпадает с ).

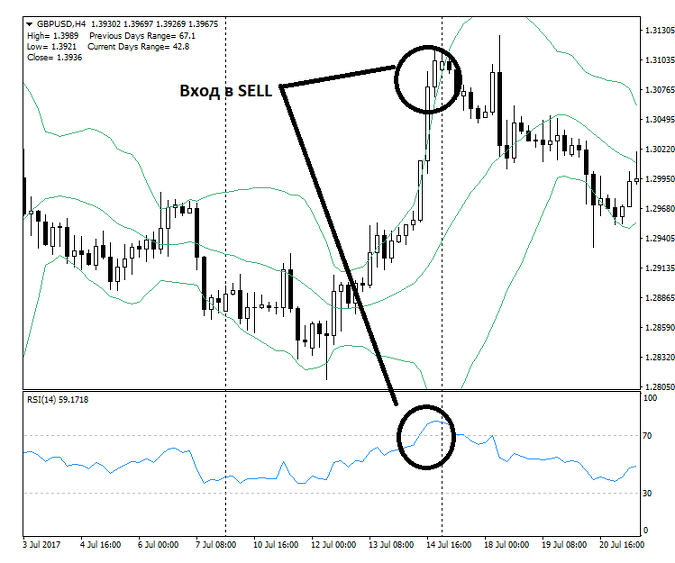
Это пример контролируемого машинного обучения, когда на основе истории предыдущих данных мы получаем предсказание. В этой статье обсудим, как можно спрогнозировать будущее, решая задачу линейной регрессии на Python. Одна из важнейших гипотез в регрессионном анализе – гипотеза о том, что коэффициент направления прямой регрессии генеральной совокупности равен нулю. В этом уравнении a – свободный член, b – коэффициент при независимой переменной. 3) Найти уравнение линейной регрессии на и изобразить соответствующую прямую на чертеже. Спрогнозировать среднюю суточную переработку сырья, когда стоимость основных фондов предприятий достигнет 9 млрд.
Давайте начнем с того, что такое https://fxglossary.ru/ и что ей не является. Модель – это просто набор правил, который позволит вам оттолкнуться от того, что вы уже знаете, и предсказать то, что вы желаете узнать. Вы хотите оттолкнуться от того, что вы уже знаете (возраст), и предсказать то, что вы хотите узнать (доход). Здесь, разумеется, будут возникать ошибки, но вы хотели бы в среднем оказываться правым, при этом постоянно не завышая и не занижая оценку дохода для возрастных диапазонов. Нужен набор правил, который точно описывает отношения между возрастом и доходом, и будет действительно моделью.
Статистическое значение слова – это оценка того, является ли отхождение от гипотезы достаточно большим, чтобы обоснованно считаться не случайным. «Значимость» в статистическом смысле не имеет ничего общего с тем, является ли результат хорошим или плохим, а означает, что результат является не случайным. Я ознакомился(-лась) с Политикой по работе с персональными данными и даю согласие на передачу и обработку моих персональных данных.
Что такое линейная регрессия?
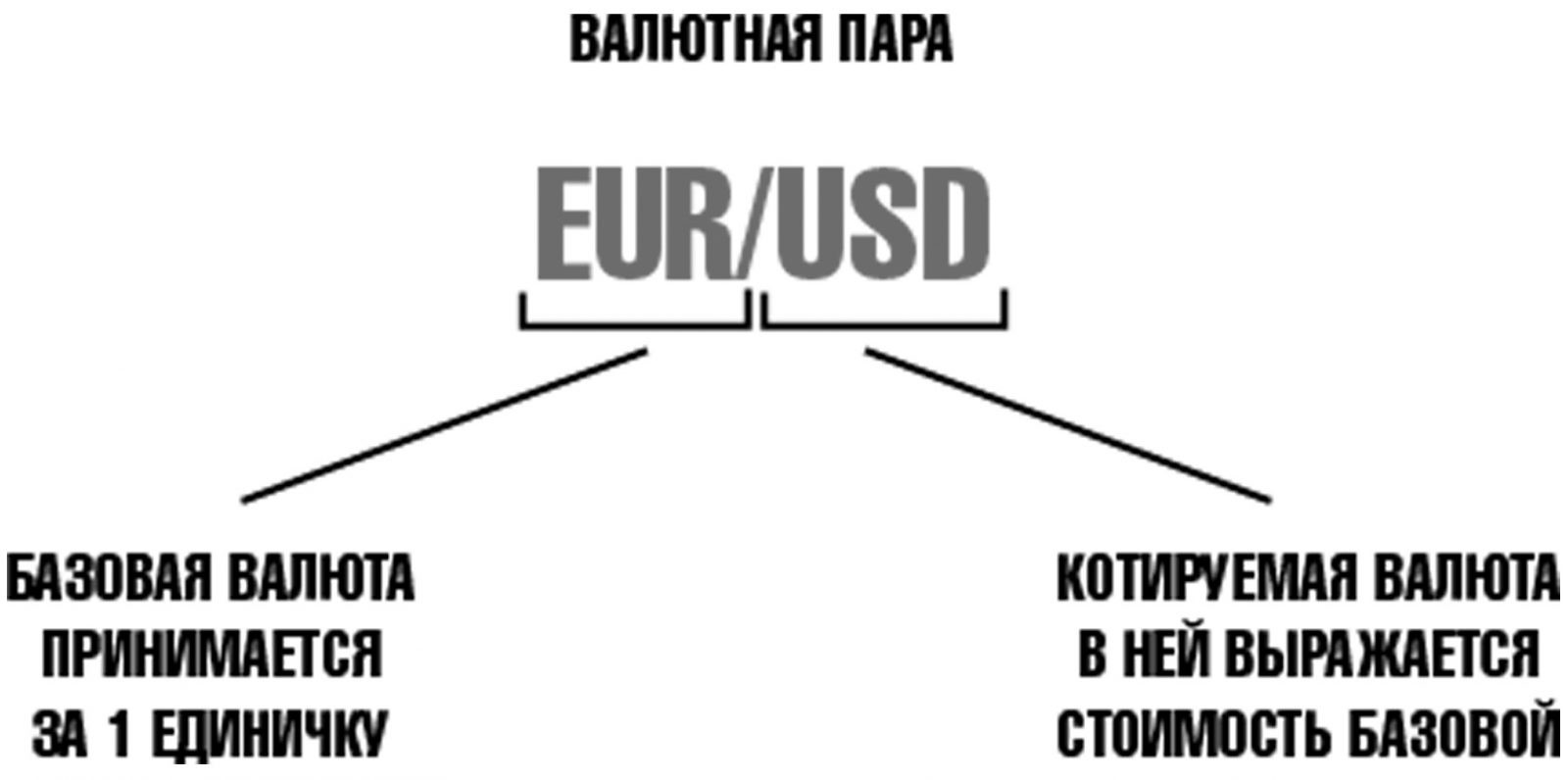
Для того, чтобы добиться желаемого результата, можно использовать выборку наблюдений, где a и b – это выборочные оценки генеральных параметров α и β. Они определяют линию регрессионного компонента в совокупности. Этот прием имеет название «метод наименьших квадратов» или МНК. Линейная регрессия в Машинном обучении – это подход к моделированию отношений между Целевой переменной и одной или несколькими “предсказывающими” переменными .
Цены на нефть могут быть предсказаны с использованием линейной регрессии. Если цель заключается в том, чтобы объяснить изменчивость выходной переменной, можно применить линейный регрессионный анализ для количественной оценки силы взаимосвязи между выходной и входными переменными. На основе этих данных определяется нужный наклон прямой и расположение относительно осей координат.

Мы начнем разговор о методах численного описания связей между количественными величинами с коэффициентов ковариации и корреляции, которые позволяют оценить силу и направление связи. Затем вы узнаете, какую дополнительную информацию о связях можно получить, построив линейную модель зависимости между величинами. Вы научитесь интерпретировать коэффициенты регрессии и узнаете, когда и как можно использовать линейные модели для предсказаний на новых данных. К концу этого модуля вы научитесь подбирать уравнение линейной модели и строить ее график с доверительной областью. О парной линейной регрессии говорят, когда установлена зависимость между двумя переменными величинами (x и y).
Всегда интерпретируйте коэффициенты корреляции и определения осторожно. Коэффициенты только определяют количество, сколько отклонения в зависимой переменной подобранная модель удаляет. Такие меры не описывают, как соответствующий ваша модель — или независимые переменные вы выбираете — для объяснения поведения переменной, которую предсказывает модель. Линейная регрессия – это алгоритм машинного обучения, который использует зависимую переменную для прогнозирования будущих результатов на основе одной или нескольких независимых переменных.
Линейная регрессия с несколькими переменными в Scikit-learn
Линейная регрессия — это это математическая модель, которая описывает связь нескольких переменных. Модели линейной регрессии представляют собой статистическую процедуру, помогающую прогнозировать будущее. Она применяется в научных сферах и в бизнесе, а в последние десятилетия используется в машинном обучении. Анализировать данные и построить оптимальную множественную линейную модель.
Линейная регрессия
То есть, вертикальное расстояние каждой точки от линии. Лучшая подгонка – это та, в которой сумма квадратов остатков оказывается минимальной. Полиномиальная регрессия — частный случай криволинейной регрессии. % Для оценки качества модели используется критерий суммы квадратов регрессионных остатков, SSE — Sum of Squared Errors. Анализ эластичности спроса по цене, характеризующей реакцию потребительского спроса на изменение цены товара.
Следует иметь в виду, что переменные могут иметь нелинейные отношения, которые не может обнаружить корреляционный анализ. Для получения дополнительной информации смотрите Линейную корреляцию. Всё, что вам нужно, – подходящие пакеты, функции и классы. Линейная регрессия – одна из важнейших и широко используемых техник регрессии. Одним из его достоинств является лёгкость интерпретации результатов.
Рассмотрим ряд понятий, связанных с моделью многомерной линейной регрессии. Прогноз или восстановление неизвестных значений зависимых переменных по заданным значениям независимых переменных. Рассчитать коэффициент детерминации для данных из примера 1.
Шаг 4: Получите результаты
Таким образом, распределение остаточных значений не должно показывать заметный шаблон. Единственное предназначение коэффициентов и, в сущности, всех чисел (технически, значений параметров), производимых регрессией – это сделать так, чтобы формула хорошо сходилась с исходными данными. Звездочка – знак умножения.Влияние нашей новой переменной «число детей», тоже линейное. Это происходит потому, что предполагаемый доход прямолинейно уменьшается на $752.35 за каждого дополнительного ребенка.
Поэтому с помощью линейной регрессии определяется оптимальный вариант расположения этой прямой. Некоторые точки все равно останутся на расстоянии, но оно должно быть минимальным. Расчет этого минимального расстояния от прямой до каждой точки называется функцией потерь. Курс рассчитан на тех, кто уже знаком с базовыми приемами анализа данных с использованием языка R и с созданием простейших .html документов при помощи rmarkdown и knitr. Уравнение линейной регрессионной модели с одним признакомУравнение линииПосле того как мы завершили процесс и смогли обучить нашу модель с помощью этой процедуры, мы можем использовать ее для новых прогнозов! Как показано на следующем рисунке, используя нашу линию оптимального соответствия и зная квадратные метры дома, мы можем использовать эту линию для прогнозирования того, сколько он будет стоить.